
¡Jueves de post! Hoy no vengo a contaros nada sobre los grupos de cálculo, para eso ya hay excelente aportaciones hechas por referentes en la comunidad como Alex Ayala, Francisco Mullor o Miguel Caballero y Fabian Torres, aunque eso no quita para que haga alguna entrada al respecto como hice con los grupos de cálculo desde Tabular Editor (aquí os dejo el link). Hoy vengo hablaros de unas funciones que no llevan ni un año entre nosotros y son las funciones ventana (INDEX, OFFSET y WINDOW). ¿Y qué son las funciones ventana? Son funciones que nos van a permitir realizar cálculos sobre un conjunto de filas dentro de una tabla. Estas funciones son especialmente útiles cuando tenemos que realizar cálculos dentro de un subconjunto de datos. Es decir, cuando queremos operar sobre una parte de los datos de una tabla.
Vamos a empezar con la función INDEX. ¿Y qué es la función INDEX? Si nos vamos a la definición de la página web de Microsoft:
Devuelve una fila en una posición absoluta, especificada por el parámetro position, dentro de la partición especificada con el orden especificado. Si la partición actual no se puede deducir como una sola partición, se pueden devolver varias filas.

Dónde:

¿Y qué quiere decir esto Javi? Pues veámoslo datos como
siempre, porque hasta aquí no hemos descubierto la pólvora como se suele decir.
Para ello, vamos a nuestro querido modelo de Contoso y lo primero que vamos a
crear es una tabla calculada con las ventas por canal, para ello creamos la
siguiente medida:

Dónde la medida Ventas Totales es:

Y obtenemos como resultado la siguiente tabla:

Ahora englobar la medida anterior en una variable, de ahí
los post anteriores. ¿Y cómo lo hacemos? De la siguiente manera:

Nota: Acordaros que toda variable se define con la sentencia
VAR y ha de tener un RETURN para devolver datos.
Vemos que el resultado anterior no ha variado:

Bien, ahora para ver el funcionamiento, vamos a crear otra
segunda tabla con la misma forma (pero distinto nombre J ):

Y vamos añadir sobre esta. Una segunda variable con la
función INDEX, para ello escribimos:

¿Qué le estamos indicando? Qué nos coja la posición 1 de la
tabla que hemos creado en el paso anterior, y nos lo devuelva, ¿no? Validamos y
vemos a ver:

Y efectivamente, nos ha devuelto la primera posición de la
tabla:

Por tanto, ¿podríamos decir que el orden en el que nos
devuelve los datos es el orden de la visualización de la tabla no? Es decir,
tal que así:

Pues vamos a verlo, si modificamos la posición 1 por la
posición 2, nos debería devolver una tabla con los datos de En Línea ¿no?

Y nos devuelve:

¿Catálogo? Si Catálogo es en teoría la posición 3 y no la 2. ¿No? Pues como imaginaréis no es la posición 3, sino que es la posición 2. ¿Qué está pasando aquí? Que los índices se ordenaron de la manera ASCENDENTE. Si vamos a la primera tabla y la ordenamos de manera ascendente vemos lo siguiente:


Que el canal Catálogo resulta que efectivamente es la posición 2 y no la 3 como nos había aparecido de manera inicial. Hasta aquí genial, pero la siguiente pregunta que nos hacemos es… ¿Y si yo quiero ordenarlo de manera descendente? ¿Podemos hacerlo? La respuesta como casi todo en este mundo, sí, para eso tenemos el tercer parámetro de la función INDEX que es ORDER BY que es un modificador del comportamiento de la función. ¿Y cómo lo hacemos? De la siguiente manera, lo primero que le indicamos es la posición 1 y en el tercer argumento le añadimos la columna por la cual queremos ordenar (que debe de existir en la tabla, lógicamente) y le añadimos la opción de DESC:

Y nos devuelve lo siguiente:

Como podemos ver, nos devuelve En Línea que ocupaba la
posición 4 en la tabla, es decir, la última posición. ¿Se entiende? ¿Y si quisiéramos
que el orden fuesen las ventas totales? Es decir, que el que más ha vendido, ¿cómo
lo hacemos? De la siguiente manera, donde hemos escrito la columna en el paso
anterior, escribimos el nombre de la columna Ventas que es calculada mediante
la métrica “Ventas Totales”:
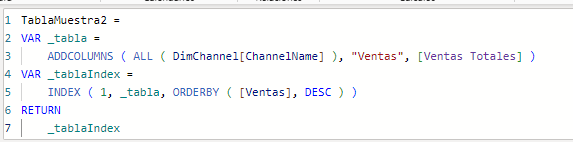
Y nos devuelve:

La función INDEX acepta otro argumento, que es el cómo tratar los espacios en blanco a la hora de ordenarlos, de momento sólo acepta el valor DEFAULT, por lo que de momento vamos a pasar de puntillas por él y vamos al siguiente, que es el argumento PARTITIONBY.
Para ver el funcionamiento del argumento PARTITIONBY, vamos
a modificar la tabla que hemos creado y en vez de que nos muestre los canales
de ventas, nos muestre el año, mes y total de las ventas, para ello:

Y nos devuelve la siguiente tabla:

Ahora vemos una tabla que nos muestra las ventas por mes y
año. Bien, ahora vamos a introducir la función INDEX como en los pasos previos
de la siguiente manera:

¿Y qué nos devuelve? Nos devuelve una tabla con MÚLTIPLES
filas en las que obtenemos el mes con mayor venta de cada año que ha habido
ventas:

Si filtramos la tabla inicial por ejemplo por el año 2007 y
ordenamos las ventas de manera descendente para ver el mes de mayor venta, el
resultado es:


Efectivamente, el mes de Noviembre para el año 2007. ¿Qué es
lo que ha hecho el argumento PARTITIONBY? Nos ha creado particiones por cada
año devolviéndonos la mayor importe de las ventas de cada uno de ellos,
tratando cada año como particiones distintas y agregándolas a la tabla.
Ahora que hemos visto la primera función de tipo ventana,
podemos decir que podríamos a ver llegado al mismo resultado con funciones DAX
corrientes y molientes, pero el código de las mismas es más extenso. Mientras
el código de las funciones ventana es más sencillo pero complejo de entender,
por lo que espero haberme explicado y a ver arrojado un poco de luz sobre las
funciones ventana.
Y hasta aquí el post de hoy, que sino sigo y sigo os dejo
sin aliento.
¡Nos vemos en los datos!





