
Aspectos Básicos del Almacenamiento de Datos
El almacenamiento de datos moderno implica cuatro fases principales:
- Ingesta de datos: Transferencia desde sistemas de origen a un almacenamiento de datos.
- Almacenamiento: Guardar datos en un formato optimizado para análisis.
- Procesamiento: Transformación en datos listos para análisis.
- Análisis y entrega: Generar informes e información empresarial a partir de los datos.
Microsoft Fabric permite realizar este proceso de forma integral, desde la ingesta hasta la visualización, mediante herramientas accesibles y tradicionales o de bajo código.
Características del Almacenamiento de Datos de Fabric
El almacenamiento en Fabric:
- Es relacional y totalmente gestionado.
- Soporta T-SQL completo para operaciones transaccionales como inserciones, actualizaciones y eliminaciones.
- Es compatible con SQL y Spark para consultas y procesamiento avanzado, como la creación de modelos de Machine Learning.
- Facilita la colaboración entre ingenieros y analistas de datos sobre datos almacenados en un único lago de datos (OneLake).
Diseño del Almacenamiento de Datos
 |
| https://learn.microsoft.com/es-es/training/modules/get-started-data-warehouse/2-understand-data-warehouse |
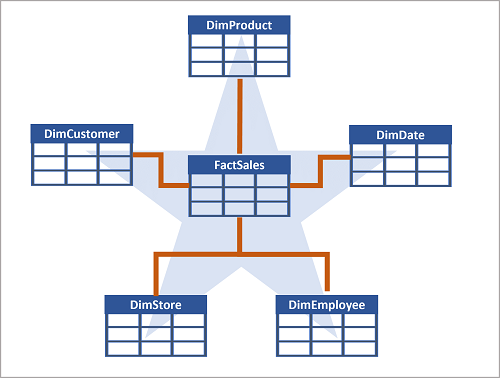
- Tablas de hechos y dimensiones: Se organizan siguiendo el modelo dimensional:
- Tablas de hechos: Contienen métricas numéricas como ventas o ingresos.
- Tablas de dimensiones: Ofrecen contexto descriptivo sobre datos de las tablas de hechos, como cliente, fecha o producto.
- Claves:
- Clave suplente: Identificador único generado internamente.
- Clave alternativa: Identificador del sistema de origen.
- Tipos especiales:
- Dimensiones de tiempo: Facilitan análisis temporal.
- Dimensiones de variación lenta: Rastreo de cambios históricos como precios o direcciones.
Esquemas del Almacenamiento de Datos
- Esquema estrella: Tablas de dimensiones directamente relacionadas con una tabla de hechos.
- Esquema copo de nieve: Normalización adicional al dividir tablas de dimensiones en tablas más específicas.
Experiencia de Almacenamiento en Fabric
- Creación del Almacenamiento:
- Se crea un almacén vacío en Fabric donde se añaden tablas, vistas y otros objetos.
- Ingesta de Datos:
- Se pueden usar canalizaciones, flujos de datos o comandos como
COPY INTOpara importar datos desde múltiples orígenes. - Clonación de tablas: Réplicas eficientes de tablas para desarrollo, pruebas o recuperación de datos.
- Se pueden usar canalizaciones, flujos de datos o comandos como
- Carga y procesamiento:
- Uso de tablas provisionales para limpieza, validación y transformación antes de cargar datos definitivos.
Consultas y Transformaciones
- Editor de consultas SQL: Soporta T-SQL con características como IntelliSense.
- Editor de consultas visuales: Experiencia de arrastrar y soltar, similar a Power Query.
- Modelos semánticos:
- Crean relaciones entre tablas y definen medidas (cálculos DAX) para análisis.
- Pueden ser modelos semánticos personalizados o predeterminados que se sincronizan automáticamente con el almacenamiento.
Visualización y Reportes
- Fabric permite explorar datos en tiempo real o generar informes de Power BI desde el almacenamiento.
- Los informes reflejan los modelos semánticos creados, facilitando análisis empresariales.
Seguridad y Supervisión
- Seguridad:
- Control de acceso basado en roles (RBAC).
- Cifrado SSL y Azure Storage Service Encryption.
- Autenticación multifactor (MFA) para mayor protección.
- Permisos:
- Roles en áreas de trabajo para acceso global.
- Permisos específicos de elementos para acceso detallado.
- Supervisión:
- Uso de Vistas de Administración Dinámica (DMV) para monitorear conexiones, sesiones y consultas:
sys.dm_exec_connections: Información de conexiones activas.sys.dm_exec_sessions: Sesiones autenticadas.sys.dm_exec_requests: Solicitudes activas.
- Uso de Vistas de Administración Dinámica (DMV) para monitorear conexiones, sesiones y consultas:
Optimización y Solución de Problemas
- Identificación de consultas largas con
sys.dm_exec_requests. - Finalización de sesiones problemáticas con el comando
KILL. - Monitoreo proactivo para asegurar rendimiento óptimo y seguridad de los datos.




